Tag: Causality
Real-time Data & Modern UXs: The Power and the Peril When Things Go Wrong

Imagine a world where user experiences adapt to you in real time. Personalized recommendations appear before you even think of them, updates happen instantaneously, and interactions flow seamlessly. This captivating world is powered by real-time data, the lifeblood of modern applications.
But this power comes at a cost. The intricate architecture behind real-time services can make troubleshooting issues a nightmare. Organizations that rely on real-time data to deliver products and services face a critical challenge: ensuring data is delivered fresh and on time. Missing data or delays can cripple the user experience and demand resolutions within minutes, if not seconds.
This article delves into the world of real-time data challenges. We’ll explore the business settings where real-time data is king, highlighting the potential consequences of issues. Then I will introduce a novel approach that injects automation into the troubleshooting process, saving valuable time and resources, but most importantly mitigating the business impact when problems arise.
Lags & Missing Data: The Hidden Disruptors Across Industries
Lags and missing data can be silent assassins, causing unseen disruptions that ripple through various industries. Let’s dig into the specific ways these issues can impact different business sectors.

Financial markets
- Trading: In high-frequency trading, even milliseconds of delay can mean the difference between a profitable and losing trade. Real-time data on market movements is crucial for making informed trading decisions.
- Fraud detection: Real-time monitoring of transactions allows financial institutions to identify and prevent fraudulent activity as it happens. Delays in data can give fraudsters a window of opportunity.
- Risk management: Real-time data on market volatility, creditworthiness, and other factors helps businesses assess and manage risk effectively. Delays can lead to inaccurate risk assessments and potentially large losses.
Supply chain management
- Inventory management: Real-time data on inventory levels helps businesses avoid stockouts and optimize inventory costs. Delays can lead to overstocking or understocking, impacting customer satisfaction and profitability.
- Logistics and transportation: Real-time tracking of shipments allows companies to optimize delivery routes, improve efficiency, and provide accurate delivery estimates to customers. Delays can disrupt logistics and lead to dissatisfied customers.
- Demand forecasting: Real-time data on customer behavior and sales trends allows businesses to forecast demand accurately. Delays can lead to inaccurate forecasts and production issues.
Customer service
- Live chat and phone support: Real-time access to customer data allows support agents to personalize interactions and resolve issues quickly. Delays can lead to frustration and longer resolution times.
- Social media monitoring: Real-time tracking of customer sentiment on social media allows businesses to address concerns and build brand reputation. Delays can lead to negative feedback spreading before it’s addressed.
- Personalization: Real-time data on customer preferences allows businesses to personalize website experiences, product recommendations, and marketing campaigns. Delays can limit the effectiveness of these efforts.
Manufacturing
- Machine monitoring: Real-time monitoring of machine performance allows for predictive maintenance, preventing costly downtime. Delays can lead to unexpected breakdowns and production delays.
- Quality control: Real-time data on product quality allows for immediate identification and correction of defects. Delays can lead to defective products reaching customers.
- Process optimization: Real-time data on production processes allows for continuous improvement and optimization. Delays can limit the ability to identify and address inefficiencies.
Other examples
- Online gaming: Real-time data is crucial for smooth gameplay and a fair playing field. Delays can lead to lag, disconnects, and frustration for players.
- Healthcare: Real-time monitoring of vital signs and patient data allows for faster diagnosis and treatment. Delays can have serious consequences for patient care.
- Energy management: Real-time data on energy consumption allows businesses and utilities to optimize energy use and reduce costs. Delays can lead to inefficient energy usage and higher costs.
- Cybersecurity: Real-time data is the backbone of modern cybersecurity, enabling rapid threat detection, effective incident response, and accurate security analytics. However, delays in the ability to see and understand this data can create critical gaps in your defenses. From attackers having more time to exploit vulnerabilities to outdated security controls and hindered automated responses, data lags can significantly compromise your ability to effectively combat cyber threats.
As we’ve seen, the consequences of lags and missing data can be far-reaching. From lost profits in financial markets to frustrated customers and operational inefficiencies, these issues pose a significant threat to business success. Having the capability to identify the root cause, impact and remediate issues with precision and speed is an imperative to mitigate the business impact.
Causely automatically captures cause and effect relationships based on real-time, dynamic data across the entire application environment. Request a demo to see it in action.
The Delicate Dance: A Web of Services and Hidden Culprits
Modern user experiences that leverage real-time data rely on complex chains of interdependent services – a delicate dance of microservices, databases, messaging platforms, and virtualized compute infrastructure. A malfunction in any one element can create a ripple effect, impacting the freshness and availability of data for users. This translates to frustrating delays, lags, or even complete UX failures.

Let’s delve into the hidden culprits behind these issues and see how seemingly minor bottlenecks can snowball into major UX problems:
Slowdown Domino with Degraded Microservice
- Scenario: A microservice responsible for product recommendations experiences high latency due to increased user traffic and internal performance degradation (e.g., memory leak, code inefficiency).
- Impact 1: The overloaded and degraded microservice takes significantly longer to process requests and respond to the database.
- Impact 2: The database, waiting for the slow microservice response, experiences delays in retrieving product information.
- Impact 3: Due to the degradation, the microservice might also have issues sending messages efficiently to the message queue. These messages contain updates on product availability, user preferences, or other relevant data for generating recommendations.
- Impact 4: Messages pile up in the queue due to slow processing by the microservice, causing delays in delivering updates to other microservices responsible for presenting information to the user.
- Impact 5: The cache, not receiving timely updates from the slow microservice and the message queue, relies on potentially outdated data.
- User Impact: Users experience significant delays in seeing product recommendations. The recommendations themselves might be inaccurate or irrelevant due to outdated data in the cache, hindering the user experience and potentially leading to missed sales opportunities. Additionally, users might see inconsistencies between product information displayed on different pages (due to some parts relying on the cache and others waiting for updates from the slow microservice).
Message Queue Backup
- Scenario: A sudden spike in user activity overwhelms the message queue handling communication between microservices.
- Impact 1: Messages pile up in the queue, causing delays in communication between microservices.
- Impact 2: Downstream microservices waiting for messages experience delays in processing user actions.
- Impact 3: The cache, not receiving updates from slow microservices, might provide outdated information.
- User Impact: Users experience lags in various functionalities – for example, slow loading times for product pages, delayed updates in shopping carts, or sluggish responsiveness when performing actions.
Cache Miss Cascade
- Scenario: A cache experiences a high rate of cache misses due to frequently changing data (e.g., real-time stock availability).
- Impact 1: The microservice needs to constantly retrieve data from the database, increasing the load on the database server.
- Impact 2: The database, overloaded with requests from the cache, experiences performance degradation.
- Impact 3: The slow database response times further contribute to cache misses, creating a feedback loop.
- User Impact: Users experience frequent delays as the system struggles to retrieve data for every request, leading to a sluggish and unresponsive user experience.
Kubernetes Lag
- Scenario: A resource bottleneck occurs within the Kubernetes cluster, limiting the processing power available to microservices.
- Impact 1: Microservices experience slow response times due to limited resources.
- Impact 2: Delays in microservice communication and processing cascade throughout the service chain.
- Impact 3: The cache might become stale due to slow updates, and message queues could experience delays.
- User Impact: Users experience lags across various functionalities, from slow page loads and unresponsive buttons to delayed updates in real-time data like stock levels or live chat messages.
Even with advanced monitoring tools, pinpointing the root cause of these and other issues can be a time-consuming detective hunt. The triage & troubleshooting process often requires a team effort, bringing together experts from various disciplines. Together, they sift through massive amounts of observability data – traces, metrics, logs, and the results of diagnostic tests – to piece together the evidence and draw the right conclusions so they can accurately determine the cause and effect. The speed and accuracy of the process is very much determined by the skills of the available resources when issues arise
Only when the root cause is understood can the responsible team make informed decisions to resolve the problem and restore reliable service.
Transforming Incident Response: Automation of the Triage & Troubleshooting Process
Traditional methods of incident response, often relying on manual triage and troubleshooting, can be slow, inefficient, and prone to human error. This is where automation comes in, particularly with the advancements in Artificial Intelligence (AI). Specifically, a subfield of AI called Causal AI presents a revolutionary approach to transforming incident response.

Causal AI goes beyond correlation, directly revealing cause-and-effect relationships between incidents and their root causes. In an environment where services rely on real-time data and fast resolution is critical, Causal AI offers significant benefits:
- Automated Triage: Causal AI analyzes alerts and events to prioritize incidents based on severity and impact. It can also pinpoint the responsible teams, freeing resources from chasing false positives.
- Machine Speed Root Cause Identification: By analyzing causal relationships, Causal AI quickly identifies the root cause, enabling quicker remediation and minimizing damage.
- Smarter Decisions: A clear understanding of the causal chain empowers teams to make informed decisions for efficient incident resolution.
Causely is leading the way in applying Causal AI to incident response for modern cloud-native applications. Causely’s technology utilizes causal reasoning to automate triage and troubleshooting, significantly reducing resolution times and mitigating business impact. Additionally, Causal AI streamlines post-incident analysis by automatically documenting the causal chain.
Beyond reactive incident response, Causal AI offers proactive capabilities that focus on measures to reduce the probability of future incidents and service disruptions, through improved hygiene, predictions and “what if” analysis.
The solution is built for the modern world that incorporates real-time data, applications that communicate synchronously and asynchronously, and leverage modern cloud building blocks (databases, caching, messaging & streaming platforms and Kubernetes).
This is just the beginning of the transformative impact Causal AI is having on incident response. As the technology evolves, we can expect even more advancements that will further streamline and strengthen organizations’ ability to continuously assure the reliability of applications.
If you would like to learn more about Causal AI and its applications in the world of real-time data and cloud-native applications, don’t hesitate to reach out.
You may also want to check out an article by Endre Sara which explains how Causely is using Causely to manage its own SaaS service, which is built around a real-time data architecture.
Related Resources
- Watch the on-demand webinar: What is Causal AI and why do DevOps teams need it?
- Read the blog: Bridging the gap between observability and automation with causal reasoning
- See causal AI in action: Request a demo of Causely
What is Causal AI & why do DevOps teams need it?

Causal AI can help IT and DevOps professionals be more productive, freeing hours of time spent troubleshooting so they can instead focus on building new applications. But when applying Causal AI to IT use cases, there are several domain-specific intricacies that practitioners and developers must be mindful of.
The relationships between application and infrastructure components are complex and constantly evolving, which means relationships and related entities are dynamically changing too. It’s important not to conflate correlation with causation, or to assume that all application issues stem from infrastructure limitations.
In this webinar, Endre Sara defines Causal AI, explains what it means for IT, and talks through specific use cases where it can help IT and DevOps practitioners be more efficient.
We’ll dive into practical implementations, best practices, and lessons learned when applying Causal AI to IT. Viewers will leave with tangible ideas about how Causal AI can help them improve productivity and concrete next steps for getting started.
Tight on time? Check out these highlights
- What is root cause and what is it not? Endre defines what we mean by “root cause” and how to know you’ve correctly identified it.
- How do you install Causely? What resources does it demand? Endre shows how easy it is.
Cause and Effect: Solving the Observability Conundrum

The pressure on application teams has never been greater. Whether for Cloud-Native Apps, Hybrid Cloud, IoT, or other critical business services, these teams are accountable for solving problems quickly and effectively, regardless of growing complexity. The good news? There’s a whole new array of tools and technologies for helping enable application monitoring and troubleshooting. Observability vendors are everywhere, and the maturation of machine learning is changing the game. The bad news? It’s still largely up to these teams to put it all together. Check out this episode of InsideAnalysis to learn how Causal AI can solve this challenge. As the name suggests, this technology focuses on extracting signal from the noise of observability streams in order to dynamically ascertain root cause analysis, and even fix mistakes automatically.
Tune in to hear Host Eric Kavanagh interview Ellen Rubin of Causely, as they explore how this fascinating new technology works.
Fools Gold or Future Fixer: Can AI-powered Causality Crack the RCA Code for Cloud Native Applications?


Can AI-powered causality crack the RCA code for cloud-native applications?
The idea of applying AI to determine causality in an automated Root Cause Analysis solution sounds like the Holy Grail, but it’s easier said than done. There’s a lot of misinformation surrounding RCA solutions. This article cuts the confusion and provides a clear picture. I will outline the essential functionalities needed for automated root cause analysis. Not only will I define these capabilities, I will also showcase some examples to demonstrate their impact.
By the end, you’ll have a clearer understanding of what a robust RCA solution powered by causal AI can offer and how it can empower your IT team to better navigate the complexities of your cloud-native environment and most importantly dramatically reduce MTTx.
The Rise (and Fall) of the Automated Root Cause Analysis Holy Grail
Modern organizations are tethered to technology. IT systems, once monolithic and predictable, have fractured into a dynamic web of cloud-native applications. This shift towards agility and scalability has come at a cost: unprecedented complexity.
Troubleshooting these intricate ecosystems is a constant struggle for DevOps teams. Pinpointing the root cause of performance issues and malfunctions can feel like navigating a labyrinth – a seemingly endless path of interconnected components, each with the potential to be the culprit.
For years, automating Root Cause Analysis (RCA) has been the elusive “Holy Grail” for service assurance, as the business consequences of poorly performing systems are undeniable, especially as organizations become increasingly reliant on digital platforms.
Despite its importance, commercially available solutions for automated RCA remain scarce. While some hyperscalers and large enterprises have the resources and capital to attempt to develop in-house solutions to address the challenge (like Capital One’s example), these capabilities are out of reach for most organizations.
See how Causely can help your organization eliminate human troubleshooting. Request a demo of the Causal AI platform.
Beyond Service Status: Unraveling the Cause-and-Effect Relations in Cloud Native Applications
Highly distributed systems, regardless of technology, are vulnerable to failures that cascade and impact interconnected components. Cloud-native environments, due to their complex web of dependencies, are especially prone to this domino effect. Imagine a single malfunction in a microservice, triggering chain reaction, disrupting related microservices. Similarly, a database issue can ripple outwards, affecting its clients and in turn everything that relies on them.
The same applies to infrastructure services like Kubernetes, Kafka, and RabbitMQ. Problems in these platforms might not always be immediately obvious because of the symptoms they cause within their domain. Furthermore symptoms manifest themselves within applications they support. The problem can then propagate further to related applications, creating a situation where the root cause problem and the symptoms they cause are separated by several layers.
Although many observability tools offer maps and graphs to visualize infrastructure and application health, these can become overwhelming during service disruptions and outages. While a sea of red icons in a topology map might highlight one or more issues, they fail to illuminate cause-and-effect relationships. Users are then left to decipher the complex interplay of problems and symptoms to work out the root cause. This is even harder to decipher when multiple root causes are present that have overlapping symptoms.
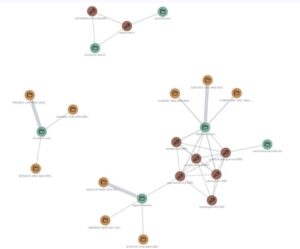
While topology maps show the status of services, they leave their users to interpret cause & effect
In addition to topology based correlation, DevOps team may also have experience of other types of correlation including event deduplication, time based correlation and path based analysis all of which attempt to reduce the noise in observability data. Don’t loose sight of the fact that this is not root cause analysis, just correlation, and correlation does not equal causation. This subject is covered further in a previous article I published Unveiling The Causal Revolution in Observability.
The Holy Grail of troubleshooting lies in understanding causality. Moving beyond topology maps and graphs, we need solutions that represent causality depicting the complex chains of cause-and-effect relationships, with clear lines of responsibility. Precise root cause identification that clearly explains the relationship between root causes and the symptoms they cause, spanning the technology domains that support application service composition, empowers DevOps teams to:
- Accelerate Resolution: By pinpointing the exact source of the issue and the symptoms that are caused by this, responsible teams are notified instantly and can prioritize fixes based on a clear understanding of the magnitude of the problem. This laser focus translates to faster resolution times.
- Minimize Triage: Teams managing impacted services are spared the burden of extensive troubleshooting. They can receive immediate notification of the issue’s origin, impact, and ownership, eliminating unnecessary investigation and streamlining recovery.
- Enhance Collaboration: With a clear understanding of complex chains of cause-and-effect relationships, teams can collaborate more effectively. The root cause owner can concentrate on fixing the issue, while impacted service teams can implement mitigating measures to minimize downstream effects.
- Automate Responses: Understanding cause and effect is also an enabler for automated workflows. This might include automatically notifying relevant teams through collaboration tools, notification systems and the service desk, as well as triggering remedial actions based on the identified problem.
Bringing This To Life With Real World Examples
The following examples will showcase the concept of causality relations, illustrating the precise relationships between root cause problems and the symptoms they trigger in interrelated components that make up application services.
This knowledge is crucial for several reasons. First, it allows for targeted notifications. By understanding the cause-and-effect sequences, the right teams can be swiftly alerted when issues arise, enabling faster resolution. Second, service owners impacted by problems can pinpoint the responsible parties. This clarity empowers them to take mitigating actions within their own services whenever possible and not waste time troubleshooting issues that fall outside of their area of responsibility.
Infra Problem Impacting Multiple Services
In this example, a CPU congestion in a Kubernetes Pod is the root cause and this causes symptoms – high latency – in application services that it is hosting. In turn, this results in high latency on other applications services. In this situation the causal relationships are clearly explained.
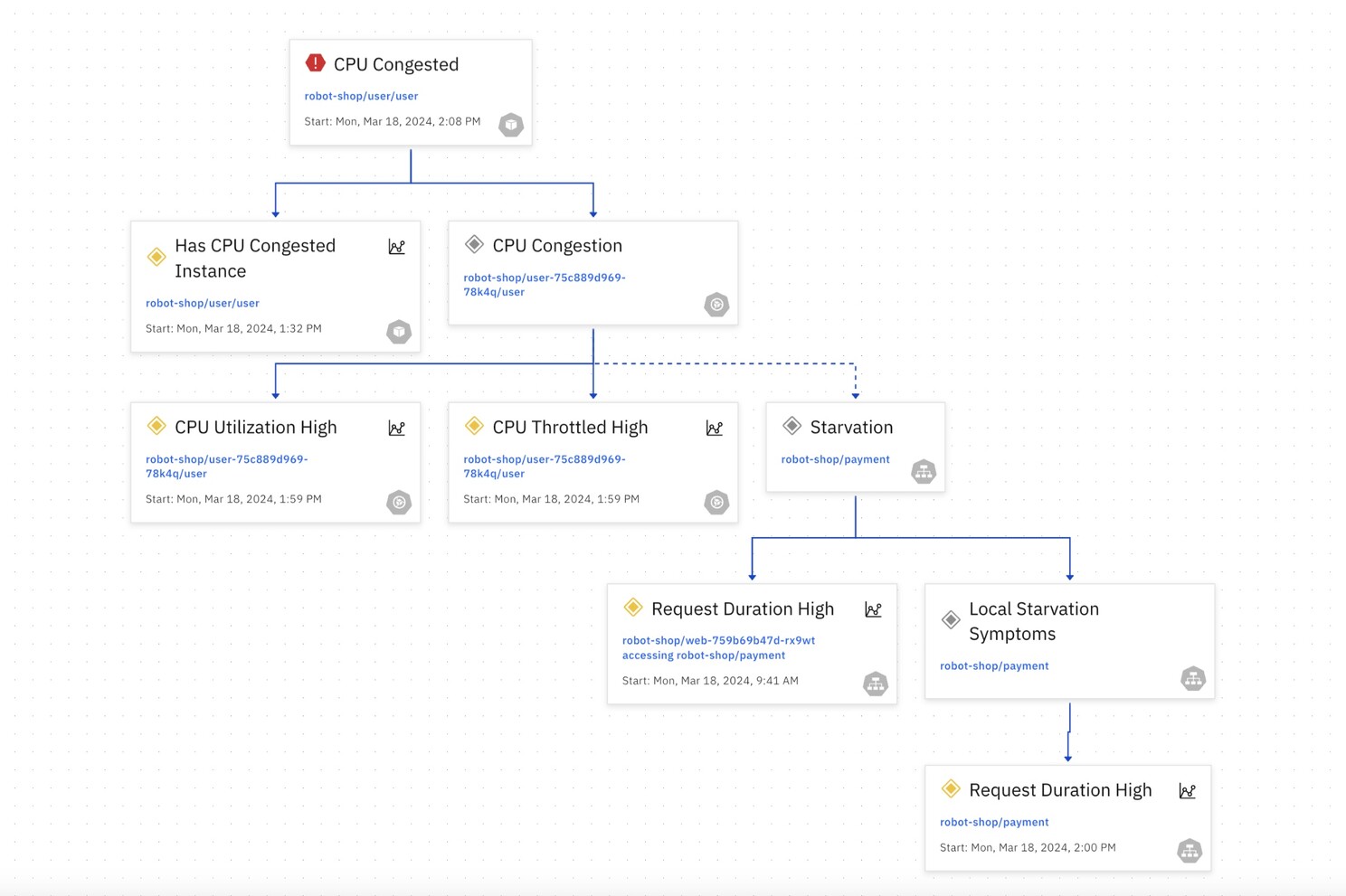
Causality graph generated by Causely
A Microservice Hiccup Leads to Consumer Lag
Imagine you’re relying on a real-time data feed, but the information you see is outdated. In this scenario, a bug within a microservice (the data producer) disrupts its ability to send updates. This creates a backlog of events, causing downstream consumers (the services that use the data) to fall behind. As a result, users/customers end up seeing stale data, impacting the overall user experience and potentially leading to inaccurate decisions. Very often the first time DevOps find out about these types of issues is when end users and customers complain about the service experience.
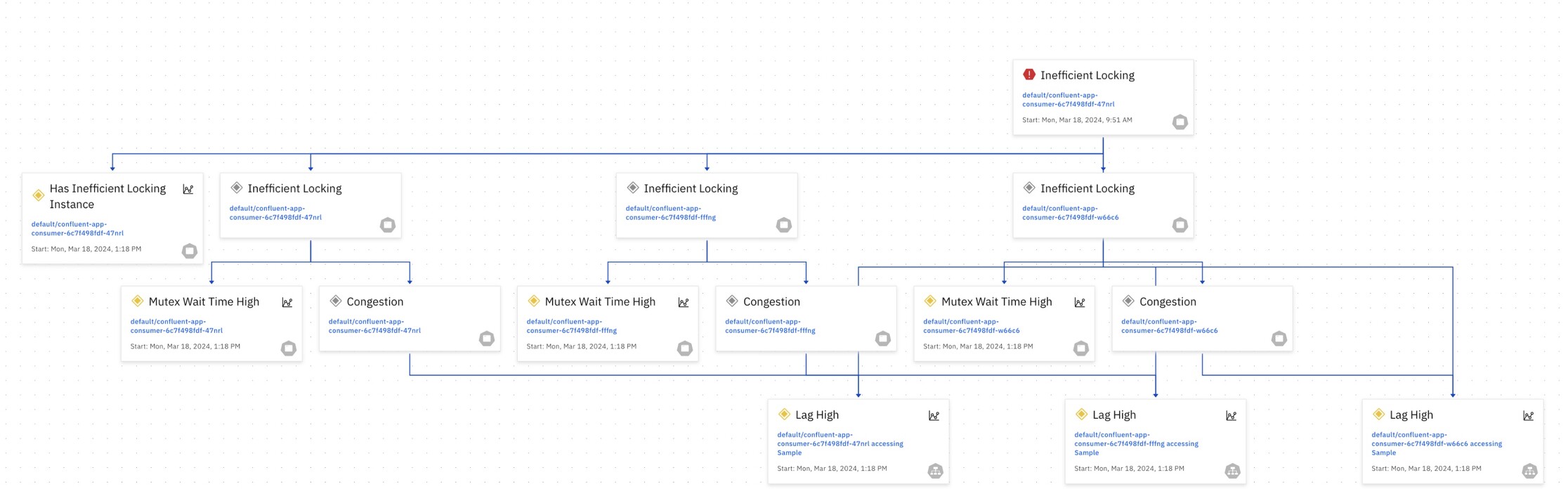
Causality graph generated by Causely
Database Problems
In this example the clients of a database are experiencing performance issues because one of the clients is issuing queries that are particularly resource-intensive. Symptoms of this include:
- Slow query response times: Other queries submitted to the database take a significantly longer time to execute.
- Increased wait times for resources: Applications using the database experience high error rate as they wait for resources like CPU or disk access that are being heavily utilized by the resource-intensive queries.
- Database connection timeouts: If the database becomes overloaded due to the resource-intensive queries, applications might experience timeouts when trying to connect.
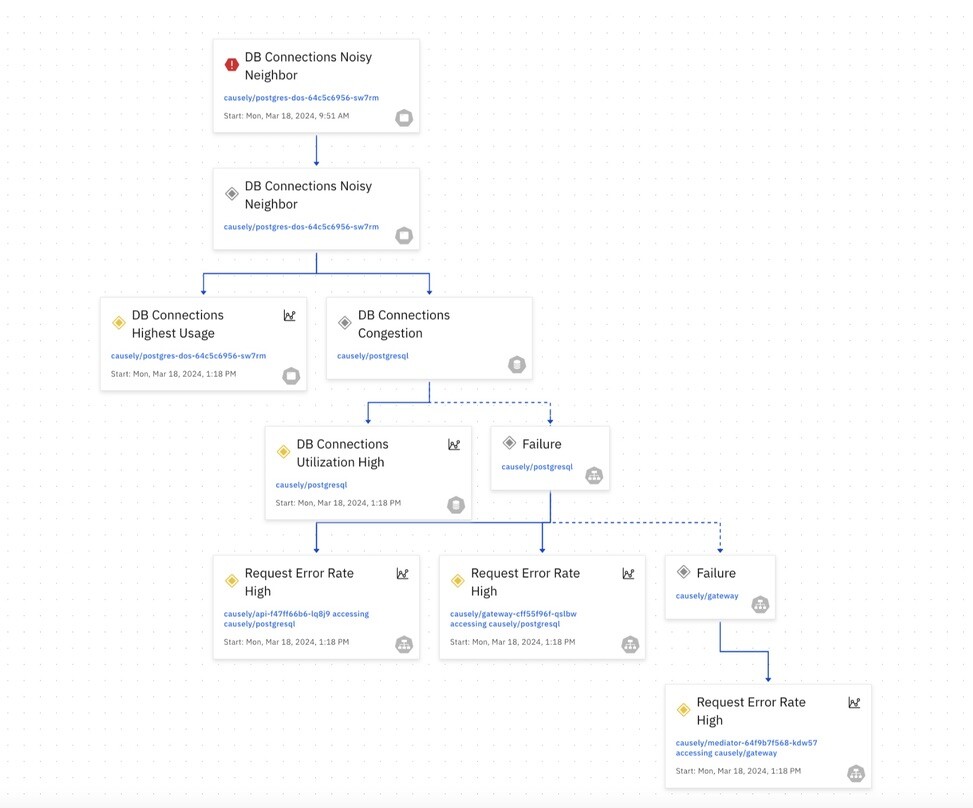
Causality graph generated by Causely
Summing Up
Cloud-native systems bring agility and scalability, but troubleshooting can be a nightmare. Here’s what you need to conquer Root Cause Analysis (RCA) in this complex world:
- Automated Analysis: Move beyond time-consuming manual RCA. Effective solutions automate data collection and analysis to pinpoint cause-and-effect relationships swiftly.
- Causal Reasoning: Don’t settle for mere correlations. True RCA tools understand causal chains, clearly and accurately explaining “why” things happen and the impact that they have.
- Dynamic Learning: Cloud-native environments are living ecosystems. RCA solutions must continuously learn and adapt to maintain accuracy as the landscape changes.
- Abstraction: Cut through the complexity. Effective RCA tools provide a clear view, hiding unnecessary details and highlighting crucial troubleshooting information.
- Time Travel:Post incident analysis requires clear explanations. Go back in time to understand “why” problems and understand the impact they had.
- Hypothesis: Understand the impact that degradation or failures in application services and infrastructure will have before they happen.
These capabilities unlock significant benefits:
- Faster Mean Time to Resolution (MTTR): Get back to business quickly.
- More Efficient Use Of Resources: Eliminate wasted time chasing the symptoms of problems and get to the root cause immediately.
- Free Up Expert Resources From Troubleshooting: Empower less specialized teams to take ownership of the work.
- Improved Collaboration: Foster teamwork because everyone understands the cause-and-effect chain.
- Reduced Costs & Disruptions: Save money and minimize business interruptions.
- Enhanced Innovation & Employee Satisfaction: Free up resources for innovation and create a smoother work environment.
- Improved Resilience: Take action now to prevent problems that could impact application performance and availability in the future
If you would like to get to avoid the glitter of “Fools Gold” and get to the Holy Grail of service assurance with automated Root Cause Analysis don’t hesitate to reach out to me directly, or contact the team at Causely today to discuss your challenges and discover how they can help you.
Related Resources
- Request a demo of the Causal AI platform from Causely
- Check out the podcast interview: Dr. Shmuel Kliger on Causely, Causal AI, and the Challenging Journey to Application Health
- Read the blog: Unveiling the Causal Revolution in Observability
Dr. Shmuel Kliger on Causely, Causal AI, and the Challenging Journey to Application Health

Dr. Shmuel Kliger, the founder of Causely.io, discusses his journey in the IT industry and the development of Causely. With a strong focus on reducing labor associated with IT operations, Dr. Kliger emphasizes the importance of understanding causality and building intelligent systems to drive insights and actions in complex IT environments. He highlights the need to focus on purpose-driven analytics and structured causality models to effectively manage and control IT systems.
Dr. Kliger also touches on the role of human interaction in influencing system behavior, mentioning the importance of defining constraints and trade-offs to guide automated decision-making processes. He envisions a future where humans provide high-level objectives and constraints, allowing the system to automatically configure, deploy, and optimize applications based on these inputs. By combining human knowledge with machine learning capabilities, Dr. Kliger aims to create a more efficient and effective approach to IT management, ultimately reducing troubleshooting time and improving system performance.
Tight on time?
Get the cliff notes from these clips:
- How to move the needle beyond stuck DevOps industry practices
- Where state-of-the-art observability is falling short
- Shmuel’s career-long focus to reduce the labor associated with IT Operations
- The importance of understanding entity relationships and causality relationships
Other ways to watch/listen
See the Causely platform in action
Cause and Defect: Root Cause Analysis with Causely
Time to Rethink DevOps Economics? The Path to Sustainable Success


As organizations transform their IT applications and adopt cloud-native architectures, scaling seamlessly while minimizing resource overheads becomes critical. DevOps teams can play a pivotal role in achieving this by embracing automation across various facets of the service delivery process.
Automation shines in areas such as infrastructure provisioning and scaling, continuous integration and delivery (CI/CD), testing, security and compliance, but the practice of automated root cause analysis remains elusive.
While automation aids observability data collection and data correlation, understanding the relationships between cause and effect still requires the judgment and expertise of skilled personnel. This work falls on the shoulders of developers and SREs who have to manually decode the signals – from metrics, traces and logs – in order to get to the root cause when the performance of services degrades.
Individual incidents can take hours and even days to troubleshoot, demanding significant resources from multiple teams. The consistency of the process can also vary greatly depending on the skills that are available when these situations occur.
Service disruptions can also have significant financial consequences. Negative customer experiences directly impact revenue, and place an additional resource burden on the business functions responsible for appeasing unhappy customers. Depending on the industry you operate in and the type of services you provide, service disruptions may result in costly chargebacks and fines, making mitigation even more crucial.

Quantifying the load of manual root cause analysis on IT teams
Shining a Light on the Root Cause Analysis Problem in DevOps
While decomposing applications into microservices through the adoption of cloud-native architectures has enabled DevOps teams to increase the velocity with which they can release new functionality, it has also created a new set of operational challenges that have a significant impact on ongoing operational expenses and service reliability.
Increased complexity: With more services comes greater complexity, more moving parts, and more potential interactions that can lead to issues. This means diagnosing the root cause of problems becomes more difficult and time-consuming.
Distributed knowledge: In cloud-native environments, knowledge about different services often resides in different teams, who have limited knowledge of the wider system architecture. As the number of services scales, finding the right experts and getting them to collaborate on troubleshooting problems becomes more challenging. This adds to the time and effort required to coordinate and carry out root cause analysis and post incident analysis.
Service proliferation fuels troubleshooting demands: Expanding your service landscape, whether through new services or simply additional instances, inevitably amplifies troubleshooting needs which translate into more resource requirements in DevOps teams for troubleshooting overtime.
Testing regimes cannot cover all scenarios: DevOps, with its CI/CD approach, releases frequent updates to individual services. This agility can reveal unforeseen interactions or behavioral changes in production, leading to service performance issues. While rollbacks provide temporary relief, identifying the root cause is crucial. Traditional post-rollback investigations might fall short due to unreproducible scenarios. Instead, real-time root cause analysis of these situations as they happen is important to ensure swift fixes and prevent future occurrences.
Telling the Story with Numbers
As cloud-native services scale, troubleshooting demands also grow exponentially, in a similar way to compounding interest on a savings account. As service footprints expand, more DevOps cycles are consumed by troubleshooting versus delivering new code, creating barriers to innovation. Distributed ownership and unclear escalation paths can also mask the escalating time that is consumed by troubleshooting.
Below is a simple model that can be customized with company-specific data to illustrate the challenge in numbers. This model helps paint a picture of the current operational costs associated with troubleshooting. It also demonstrates how these are going to escalate over time, driven by the growth in cloud-native services (more microservices, serverless functions, etc).
The model also illustrates the impact of efficiency gains through automation versus the current un-optimized state. The gap highlights the size of the opportunity available to create more cycles for productive development while reducing the need for additional headcount into the future, by automating troubleshooting.



This model illustrates the costs and impact of efficiency gains that can be achieved through automated root cause analysis
Beyond the cost of human capital, there are a number of other costs that have a direct impact on troubleshooting costs. These include the escalating costs of infrastructure and third-party SaaS services, dedicated to the management of observability data. These are well publicized and highlighted in a recent article published by Causely Founding Engineer Endre Sara that discusses avoiding the pitfalls of escalating costs when building out Causely’s own SaaS offering.
While DevOps have a cost, they pale in comparison to the financial consequences of service disruptions. With automated root cause analysis, DevOps teams can mitigate these risks, saving the business time, money and reputation.
Future iterations of the model will account for these additional dimensions.
If you would like to put your data to work and see the quantifiable benefits of automated root cause analysis in numbers, complete the short form to get started.
Translating Theory into Reality
Did you know companies like Meta and Capital One automate root cause analysis in devops, achieving 50% faster troubleshooting? However, the custom solutions built by these industry giants require vast resources and deep expertise in data science to build and maintain, putting automated root cause analysis capabilities out of reach for most companies.
The team at Causely are changing this dynamic. Armed with decades of experience – applying AI to the management of distributed systems, networks, and application resource management – they offer a powerful SaaS solution that removes the roadblocks to automated root cause analysis in DevOps environments. The Causely solution enables
- Clear, explainable insights: Instead of receiving many notifications when issues arise, teams receive clear notifications that explain the root cause along with the symptoms that led to these conclusions.
- Faster resolution times: Teams can get straight to work on problem resolution and even automate resolutions, versus spending time diagnosing problems.
- Business impact reduction: Problems can be prevented, early in their cycle, from escalating into critical situations that might otherwise have resulted in significant business disruption.
- Clearer communication & collaboration: RCA pinpoints issue owners, reducing triage time and wasted efforts from other teams.
- Simplified post-incident analysis: All of the knowledge about the cause and effect of prior problems is stored and available to simplify the process of post incident analysis and learning.
Wrapping Up
In this article we discussed the key challenges associated with troubleshooting and highlighted the cost implications of today’s approach. Addressing these issues is important because the business consequences of today’s approach are significant.
- Troubleshooting is costly because it consumes the time of skilled resources.
- Troubleshooting steals time from productive activities which impacts the ability of DevOps to deliver new capabilities.
- Service disruptions have business consequences: The longer they persist, the bigger the impact to customers and business.
If you don’t clearly understand your future resource requirements and costs associated with troubleshooting as you scale out cloud-native services, the model we’ve developed provides a simple way to capture this.
Want to see quantifiable benefits from automated root cause analysis?
Turn “The Optimized Mode of Operation” in the model from vision to reality with Causely.
The Causely service enables you to measure and showcase the impact of automating RCA in your organization. Through improved service performance and availability, faster resolution times, and improved team efficiency, the team will show you the “art of the possible.”
Related Resources
- Watch the video: Mission Impossible: Cracking the Code of Complex Tracing Data
- Read the blog: Eating Our Own Dog Food: Causely’s Journey with OpenTelemetry & Causal AI
- Request a demo: See Causely in action
What is causal AI?
Moving Beyond Traditional RCA In DevOps

Reposted with permission from LinkedIn.

Modernization Of The RCA Process
Over the past month, I have spent a significant amount of time researching what vendors and customers are doing in the devops space to streamline the process of root cause analysis (RCA).
My conclusion is that the underlying techniques and processes used in operational environments today to perform RCA remain human centric. As a consequence troubleshooting remains complex, resource intensive and requires skilled practitioners to perform the work.
So, how do we break free from this human bottleneck? Brace yourselves for a glimpse into a future powered by AI. In this article, we’ll dissect the critical issues, showcase how cutting-edge AI advancements can revolutionize RCA, and hear first hand from operations and engineering leaders who have shared their perspective on this transformative tech, having experienced the capabilities first hand.
Troubleshooting In The Cloud Native Era With Monitoring & Observability
Troubleshooting is hard because when degradations or failures occur in components of a business service, they spread like a disease to related service entities which also become degraded or fail.
This problem is amplified in the world of cloud-native applications where we have decomposed business logic into many separate but interrelated service entities. Today an organization might have hundreds or thousands of interrelated service entities (micro services, databases, caches, messaging…).
To complicate things even further, change is a constant – code changes, fluctuating demand patterns, and the inherent unpredictability of user behavior. These changes can result in service degradations or failures.
Testing for all possible permutations in this ever-shifting environment is akin to predicting the weather on Jupiter – an impossible feat – amplifying the importance of a fast, effective and consistent root cause analysis process, to maintain the availability, performance and operational resilience of business systems.
While observability tools have made strides in data visualization and correlation, their inherent inability to explain the cause-and-effect relationships behind problems leaves us dependent on human expertise to navigate the vast seas of data to determine the root cause of service degradation and failures.
This dependence becomes particularly challenging due to siloed devops teams that have responsibility for supporting individual service entities within the complex web of services entities that make up business services. In this context individual teams may frequently struggle to pinpoint the source of service degradation or failure as the entity they support might be the culprit, or a victim of another service entity’s malfunction.
The availability of knowledge and skills within these teams also fluctuate due to business priorities, vacations, holidays, and even the daily working cycles. This resource variability can lead to significant inconsistencies in problem identification and resolution times.
Causal AI To The Rescue: Automating The Root Cause Analysis Process For Cloud Native DevOps
For those who are not aware, Causal AI is a distinct field in Artificial Intelligence. It is already used extensively in many different industries but until recently there has been no application of the technology in the world of devops.
Causely is a new pioneer championing the use of Causal AI working in the area of cloud-native applications. Their platform embodies an understanding of causality so that when service entities are degraded or failing and affecting other service entities that make up business services, it can explain the cause and effect, by showing the relationship between the problem and the symptoms that this causes.
Through this capability, the team with responsibility for the failing or degraded service can be immediately notified and get to work on resolving the problem. Other teams might also be provided with notifications to let them know that their services are affected, along with an explanation for why this occurred. This eliminates the need for complex triage processes that would otherwise involve multiple teams and managers to orchestrate the process.
Understanding the cause-and-effect relationships in software systems serves as an enabler for automated remediation, predictive maintenance, and planning/gaming out operational resilience.
By using software in this way to automate the process of root cause analysis, organizations can reduce the time and effort and increase the consistency in the troubleshooting process, all of which leads to lower operational costs, improved service availability and less business disruption.
Customer Reactions: Unveiling the Transformative Impact of Causal AI for Cloud-Native DevOps
After sharing insights into Causely’s groundbreaking approach to root cause analysis (RCA) with operational and engineering leaders across various organizations, I’ve gathered a collection of anecdotes that highlight the profound impact this technology is poised to have in the world of cloud-native devops.
Streamlined Incident Resolution and Reduced Triage
“By accurately pinpointing the root cause, we can immediately engage the teams directly responsible for the issue, eliminating the need for war rooms and time-consuming triage processes. This ability to swiftly identify the source of problems and involve the appropriate teams will significantly reduce the time to resolution, minimizing downtime and its associated business impacts.”
Automated Remediation: A Path to Efficiency
“Initially, we’d probably implement a ‘fix it’ button that triggers remediation actions manually. However, as we gain confidence in the results, we can gradually automate the remediation process. This phased approach ensures that we can seamlessly integrate Causely into our existing workflows while gradually transitioning towards a more automated and efficient remediation strategy.”
Empowering Lower-Skilled Team Members
“Lower-skilled team members can take on more responsibilities, freeing up our top experts to focus on code development. By automating RCA tasks and providing clear guidance for remediation, Causely will empower less experienced team members to handle a wider range of issues, allowing senior experts to dedicate their time to more strategic initiatives.”
Building Resilience through Reduced Human Dependency
“Causely will enable us to build greater resilience into our service assurance processes by reducing our reliance on human knowledge and intuition. By automating RCA and providing data-driven insights, Causely will help us build a more resilient infrastructure that is less susceptible to human error and fluctuations in expertise.”
Enhanced Support Beyond Office Hours
“We face challenges maintaining consistent support outside of office hours due to reduced on-call expertise. Causely will enable us to handle incidents with the same level of precision and efficiency regardless of the time of day. Causely’s ability to provide automated RCA and remediation even during off-hours ensures that organizations can maintain a high level of service continuity around the clock.”
Automated Runbook Creation and Maintenance
“I was planning to create runbooks to guide other devops team members through troubleshooting processes. Causely can automatically generate and maintain these runbooks for me. This automated runbook generation eliminates the manual effort required to create and maintain comprehensive troubleshooting guides, ensuring that teams have easy access to the necessary information when resolving issues.”
Simplified Post-Incident Analysis
“Post-incident analysis will become much simpler as we’ll have a detailed record of the cause and effect for every incident. Causely’s comprehensive understanding of cause and effect provides a valuable resource for post-incident analysis, enabling us to improve processes, and prevent similar issues from recurring.”
Faster Problem Identification and Reduced Business Impacts
“Problems will be identified much faster, and there will be fewer business consequences. By automating RCA and providing actionable insights, Causely can significantly reduce the time it takes to identify and resolve problems, minimizing their impact on business operations and customer experience.”
These anecdotes underscore the transformative potential of Causely, offering a compelling vision of how root cause analysis is automated, remediation is streamlined, and operational resilience in cloud-native environments is enhanced. As Causely progresses, the company’s impact on the IT industry is poised to be profound and far-reaching.
Summing Things Up
Troubleshooting in cloud-native environments is complex and resource-intensive, but Causal AI can automate the process, streamline remediation, and enhance operational resilience.
If you would like to learn more about how Causal AI might benefit your organization, don’t hesitate to reach out to me or Causely directly.
Related Resources
- Learn about the causal AI platform from Causely
- Watch the video: Troubleshooting cloud-native applications with Causely
- Request a demo to see Causely in action
Unveiling the Causal Revolution in Observability

Reposted with permission from LinkedIn.
OpenTelemetry and the Path to Understanding Complex Systems
Decades ago, the IETF’s (Internet Engineering Task Force) developed an innovative protocol, SNMP, revolutionizing network management. This standardization spurred a surge of innovation, fostering a new software vendor landscape dedicated to streamlining operational processes in network management, encompassing Fault, Configurations, Accounting, Performance, and Security (FCAPS). Today, SNMP reigns as the world’s most widely adopted network management protocol.
On the cusp of a similar revolution stands the realm of application management. For years, the absence of management standards compelled vendors to develop proprietary telemetry for application instrumentation, to enable manageability. Many of the vendors also built applications to report on and visualize managed environments, in an attempt to streamline the processes of incident and performance management.
OpenTelemetry‘s emergence is poised to transform the application management market dynamics in a similar way by commoditizing application telemetry instrumentation, collection, and export methods. Consequently, numerous open-source projects and new companies are emerging, building applications that add value around OpenTelemetry.
This evolution is also compelling established vendors to embrace OpenTelemetry. Their futures hinge on their ability to add value around this technology, rather than solely providing innovative methods for application instrumentation.

Adding Value Above OpenTelemetry
While OpenTelemetry simplifies the process of collecting and exporting telemetry data, it doesn’t guarantee the ability to pinpoint the root cause of issues. This is because understanding the causal relationships between events and metrics requires more sophisticated analysis techniques.
Common approaches to analyzing OpenTelemetry data that get devops teams closer to this goal include:
- Visualization and Dashboards: Creating effective visualizations and dashboards is crucial for extracting insights from telemetry data. These visualizations should present data in a clear and concise manner, highlighting trends, anomalies, and relationships between metrics.
- Correlation and Aggregation: To correlate logs, metrics, and traces, you need to establish relationships between these data streams. This can be done using techniques like correlation IDs or trace identifiers, which can be embedded in logs and metrics to link them to their corresponding traces.
- Pattern Recognition and Anomaly Detection: Once you have correlated data, you can apply pattern recognition algorithms to identify anomalies or outliers in metrics, which could indicate potential issues. Anomaly detection tools can also help identify sudden spikes or drops in metrics that might indicate performance bottlenecks or errors.
- Machine Learning and AI: Machine learning and AI techniques can be employed to analyze telemetry data and identify patterns, correlations, and anomalies that might be difficult to detect manually. These techniques can also be used to predict future performance or identify potential issues before they occur.
While all of these techniques might help to increase the efficiency of the troubleshooting process, human expertise is still essential for interpreting and understanding the results. This is because these approaches to analyzing telemetry data are based on correlation and lack an inherent understanding of cause and effect (causation).
Avoiding The Correlation Trap: Separating Coincidence from Cause and Effect
In the realm of analyzing observability data, correlation often takes center stage, highlighting the apparent relationship between two or more variables. However, correlation does not imply causation, a crucial distinction that software-driven causal analysis can effectively address and results in a better outcome in the following ways:
Operational Efficiency And Control: Correlation-based approaches often leave us grappling with the question of “why,” hindering our ability to pinpoint the root cause of issues. This can lead to inefficient troubleshooting efforts, involving multiple teams in a devops environment as they attempt to unravel the interconnectedness of service entities.
Software-based causal analysis empowers us to bypass this guessing game, directly identifying the root cause and enabling targeted corrective actions. This not only streamlines problem resolution but also empowers teams to proactively implement automations to mitigate future occurrences. It also frees up the time of experts in the devops organizations to focus on shipping features and working on business logic.
Consistency In Responding To Adverse Events: The speed and effectiveness of problem resolution often hinge on the expertise and availability of individuals, a variable factor that can delay critical interventions. Software-based causal analysis removes this human dependency, providing a consistent and standardized approach to root cause identification.
This consistency is particularly crucial in distributed devops environments, where multiple teams manage different components of the system. By leveraging software, organizations can ensure that regardless of the individuals involved, problems are tackled with the same level of precision and efficiency.
Predictive Capabilities And Risk Mitigation: Correlations provide limited insights into future behavior, making it challenging to anticipate and prevent potential problems. Software-based causal analysis, on the other hand, unlocks the power of predictive modeling, enabling organizations to proactively identify and address potential issues before they materialize.
This predictive capability becomes increasingly valuable in complex cloud-native environments, where the interplay of numerous microservices and data pipelines can lead to unforeseen disruptions. By understanding cause and effect relationships, organizations can proactively mitigate risks and enhance operational resilience.
Conclusion
OpenTelemetry marks a significant step towards standardized application management, laying a solid foundation for a more comprehensive understanding of complex systems. However, to truly unlock the full potential, the integration of software-driven causal analysis, also referred to as Causal AI, is essential. By transcending correlation, software-driven causal analysis empowers devops organizations to understand cause and effect of system behavior, enabling proactive problem detection, predictive maintenance, operational risk mitigation and automated remediation.
The founding team of Causely participated in the standards-driven transformation that took place in the network management market more than two decades ago at a company called SMARTS. The core of their solution was built on Causal AI. SMARTS became the market leader of Root Cause Analysis in networks and was acquired by EMC in 2005. The team’s rich experience in Causal AI is now being applied at Causely, to address the challenges of managing cloud native applications.
Causely’s embrace of OpenTelemetry stems from the recognition that this standardized approach will only accelerate the advancement of application management. By streamlining telemetry data collection, OpenTelemetry creates a fertile ground for Causal AI to flourish.
If you are intrigued and would like to learn more about Causal AI the team at Causely would love to hear from you, so don’t hesitate to get in touch.
DevOps may have cheated death, but do we all need to work for the king of the underworld?

Sisyphus. Source: https://commons.wikimedia.org/wiki/File:Punishment_sisyph.jpg
This blog was originally posted on LinkedIn.
How causality can eliminate human troubleshooting
Tasks that are both laborious and futile are described as Sisyphean. In Greek mythology, Sisyphus was the founder and king of Ephyra (now known as Corinth). Hades – the king of the underworld – punished him for cheating death twice by forcing him to roll an immense boulder up a hill only for it to roll back down every time it neared the top, repeating this action for eternity.
The goal of application support engineers is to identify, detect, remediate, and prevent failures or violations of service level objectives (SLOs). DevOps have been pronounced dead by some, but still seem to be tasked with building and running apps at scale. Observability tools provide comprehensive monitoring, proactive alerting, anomaly detection, and maybe even some automation of routine tasks, such as scaling resources. But they leave the Sisyphean heavy lifting job of troubleshooting, incident response and remediation, as well as root cause analysis and continuous improvements during or after an outage, to humans.
Businesses are changing rapidly; application management has to change
Today’s environments are highly dynamic. Businesses must be able to rapidly adjust their operations, scale resources, deliver sophisticated services, facilitate seamless interactions, and adapt quickly to changing market conditions.
The scale and complexity of application environments is expanding continuously. Application architectures are increasingly complex, with organizations relying on a larger number of cloud services from multiple providers. There are more systems to troubleshoot and optimize, and more data points to keep track of. Data is growing exponentially across all technology domains affecting its collection, transport, storage, and analysis. Application management relies on technologies that try to capture this growing complexity and volume, but those technologies are limited by the fact that they’re based on data and models that assume that the future will look a lot like the past. This approach can be effective in relatively static environments where patterns and relationships remain consistent over time. However, in today’s rapidly changing environments, this will fail.
As a result, application support leaders find it increasingly difficult to manage the increasing complexity and growing volume of data in cloud-native technology stacks. Operating dynamic application environments is simply beyond human scale, especially in real time. The continuous growth of data generated by user interactions, cloud instances, and containers requires a shift in mindset and management approaches.
Relationships between applications and infrastructure components are complex and constantly changing
A major reason that relationships and related entities are constantly changing is because of the complicated and dynamic nature of application and infrastructure components. Creating a new container and destroying it takes seconds to minutes each time, and with every change includes changes to tags, labels, and metrics. This demonstrates the sheer volume, cardinality, and complexity of observability datasets.
The complexity and constant change within application environments is why it can take days to figure out what is causing a problem. It’s hard to capture causality in a dataset that’s constantly changing based on new sets of applications, new databases, new infrastructure, new software versions, etc. As soon as you identify one correlation, the landscape has likely already changed.

Correlation is not causation. Source: https://twitter.com/OdedRechavi/status/1442759942553968640/photo/1
Correlation is NOT causation
The most common trap that people fall into is assuming correlation equals causation. Correlation and causation both indicate a relationship exists between two occurrences, but correlation is non-directional, while causation implies direction. In other words, causation concludes that one occurrence was the consequence of another occurrence.
It’s important to clearly distinguish correlation from causation before jumping to any conclusions. Neither pattern identification nor trend identification is causation. Even if you apply correlation on top of an identified trend, you won’t get the root cause. Without causality, you cannot understand the root cause of a set of observations and without the root cause, the problem cannot be resolved or prevented in the future.
Blame the network. Source @ioshints
Don’t assume that all application issues are caused by infrastructure
In application environments, the conflation between correlation and causation often manifests through assumptions that symptoms propagate on a predefined path – or, to be more specific, that all application issues stem from infrastructure limitations or barriers. How many times have you heard that it is always “the network’s fault”?
In a typical microservices environment, application support teams will start getting calls and alerts about various clients experiencing high latency, which will also lead to the respective SLOs being violated. These symptoms can be caused by increased traffic, inefficient algorithms, misconfigured or insufficient resources or noisy neighbors in a shared environment. Identifying the root cause across multiple layers of the stack, typically managed by different application and infrastructure teams, can be incredibly difficult. It requires not just observability data including logs, metrics, time-series anomalies, and topological relationships, but also the causality knowledge to reason if this is an application problem impacting the infrastructure vs. an infrastructure problem impacting the applications, or even applications and microservices impacting each other.
Capture knowledge, not just data
Gathering more data points about every aspect of an application environment will not enable you to learn causality – especially in a highly dynamic application environment. Causation can’t be learned only by observing data or generating more alerts. It can be validated or enhanced as you get data, but you shouldn’t start there.
Think failures/defects, not alerts
Start by thinking about failures/defects instead of the alerts or symptoms that are being observed. Failures require intervention and either recur or currently cannot be resolved. Only when you know the failures you care about should you look at the alerts or symptoms that may be caused by them.
Root cause analysis (RCA) is the problem of inferring failures from an observed set of symptoms. For example, bad choices of algorithms or data structures may cause service latency, high CPU or high memory utilization as observed symptoms and alerts. The root cause of bad choices of algorithms and data structures can be inferred from the observed symptoms.
Causal AI is required to solve the RCA problem
Causal AI is an artificial intelligence system that can explain cause and effect. Unlike predictive AI models that are based on historical data, systems based on causal AI provide insight by identifying the underlying web of causality for a given behavior or event. The concept of causal AI and the limits of machine learning were raised by Judea Pearl, the Turing Award-winning computer scientist and philosopher, in The Book of Why: The New Science of Cause and Effect.
“Machines’ lack of understanding of causal relations is perhaps the biggest roadblock to giving them human-level intelligence.”
– Judea Pearl, The Book of Why
Causal graphs are the best illustration of causal AI implementations. A causal graph is a visual representation that usually shows arrows to indicate causal relationships between different events across multiple entities.
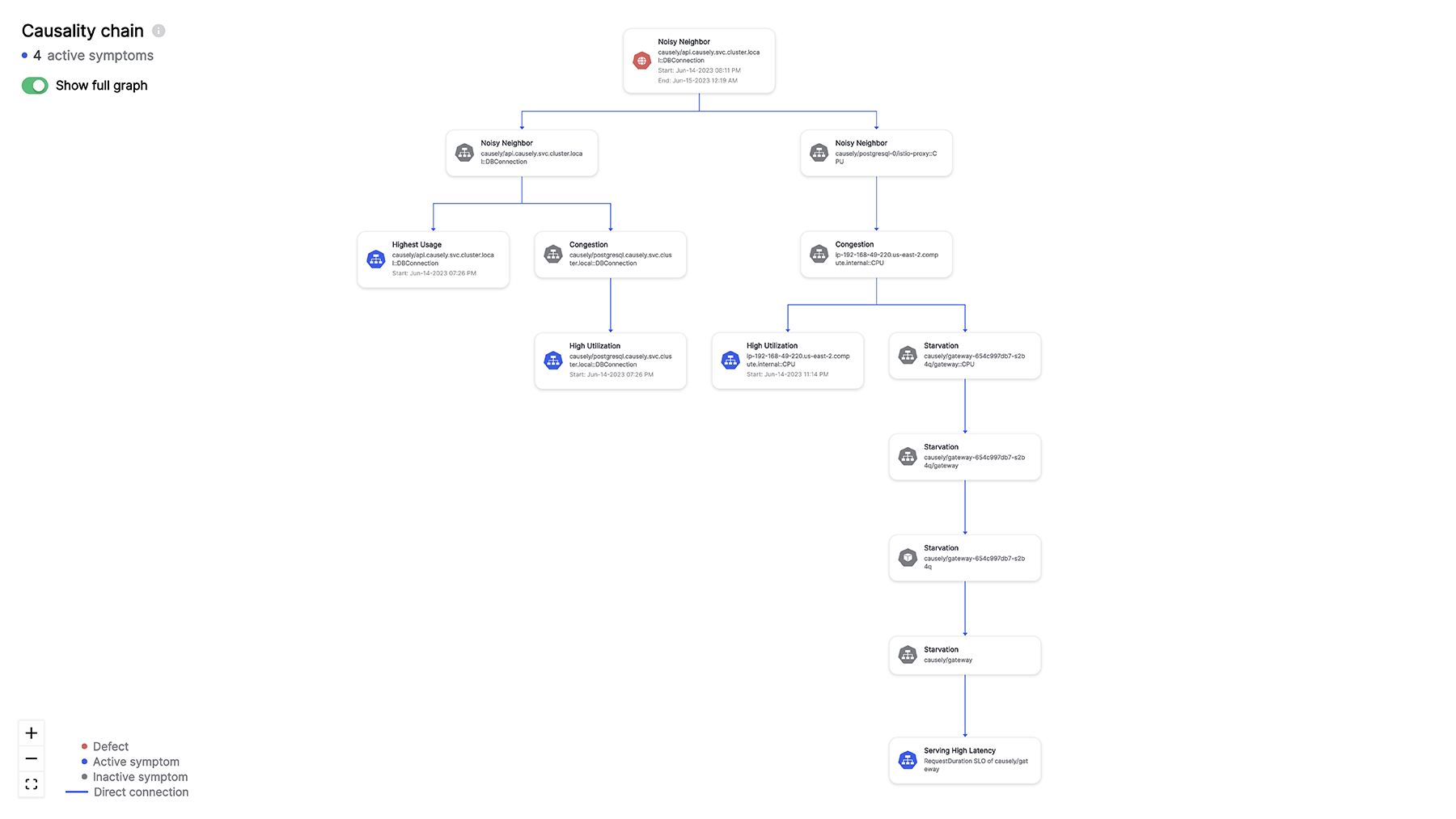
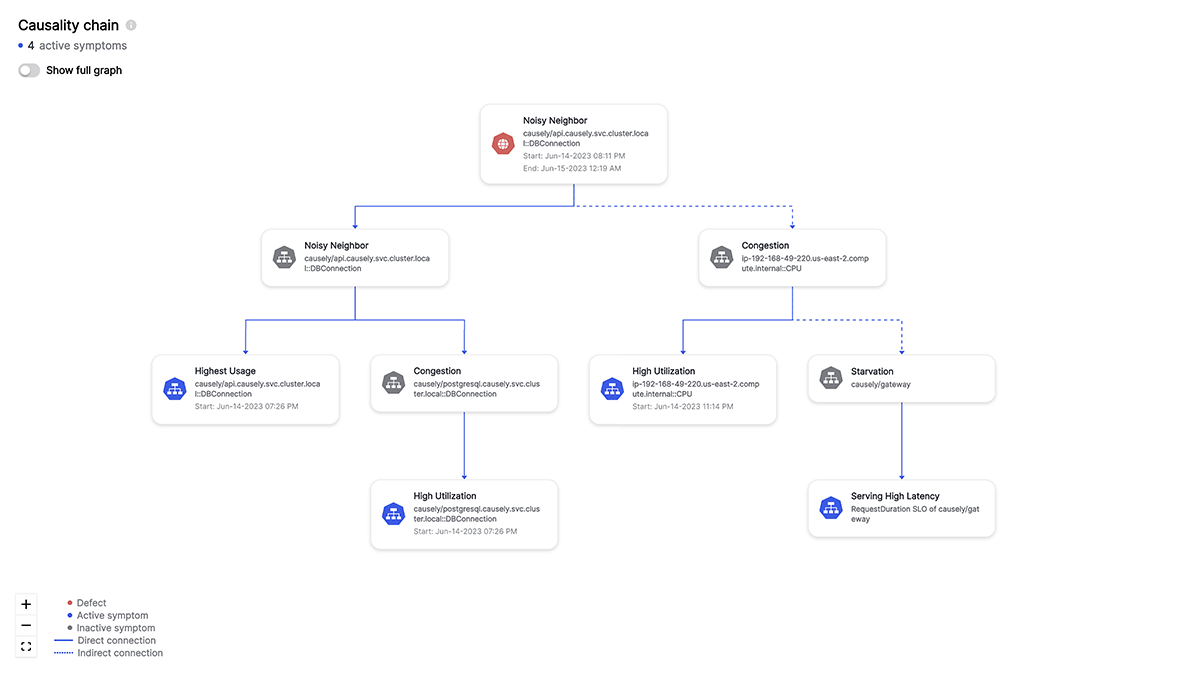
Database Noisy Neighbor causing service and infrastructure symptoms
In this example, we are observing multiple clients experiencing errors and service latency, as well as neighboring microservices suffering from not getting enough compute resources. Any attempt to tackle the symptoms independently, by for instance increasing CPU limit, or horizontal scaling the impacted service, will not solve the REAL problem.
The best explanation for this combination of observed symptoms is the problem with the application’s interaction with the database. The root cause can be inferred even when not all the symptoms are observed. Instead of troubleshooting individual client errors or infrastructure symptoms, the application support team can focus on the root cause and fix the application.
Capturing this human knowledge in a declarative form allows causal AI to reason about not just the observed symptoms but also the missing symptoms in the context of the causality propagations between application and infrastructure events. You need to have a structured way of capturing the knowledge that already exists in the minds and experiences of application support teams.
Wrapping up
Hopefully this blog helps you to begin to think about causality and how you can capture your own knowledge in causality chains like the one above. Human troubleshooting needs to be relegated to history and replaced with automated causality systems.
This is something we think about a lot at Causely, and would love any feedback or commentary about your own experiences trying to solve these kinds of problems.
Related resources
- Read the blog: One million ways to slow down your application response time and throughput
- Learn about Causely’s causal AI platform for IT
- Get early access to Causely for cloud-native applications